

|
|
This page describes some data I scraped about slot machines.
I built a DB with slot machines and additional data where available.

There are 2,865 slot machines from 4 manufacturers.
I pulled YouTube channels that play slot machines. Then I used the YouTube API to pull all the video titles for these channels.
import requests
from tqdm import tqdm
API_KEY = INSERT_API_KEY
# CHANNEL_USERNAME = "VegasMatt"
data = list()
for CHANNEL_USERNAME in tqdm(handles):
url = f"https://www.googleapis.com/youtube/v3/channels?part=id&forHandle={CHANNEL_USERNAME}&key={API_KEY}&part=id"
response = requests.get(url).json()
channel_id = response["items"][0]["id"]
url = f"https://www.googleapis.com/youtube/v3/channels?part=contentDetails&id={channel_id}&key={API_KEY}"
response = requests.get(url).json()
uploads_playlist = response["items"][0]["contentDetails"]["relatedPlaylists"]["uploads"]
url = f"https://www.googleapis.com/youtube/v3/playlistItems?part=snippet&playlistId={uploads_playlist}&maxResults=50&key={API_KEY}"
response = requests.get(url).json()
for item in response["items"]:
data.append({
"channel": CHANNEL_USERNAME,
"video": item["snippet"]["title"],
})
i = 0
while i < 50 and "nextPageToken" in response and len(response["nextPageToken"]) > 0:
next_page_token = response["nextPageToken"]
url = f"https://www.googleapis.com/youtube/v3/playlistItems?part=snippet&playlistId={uploads_playlist}&maxResults=50&key={API_KEY}&pageToken={next_page_token}"
response = requests.get(url).json()
for item in response["items"]:
data.append({
"channel": CHANNEL_USERNAME,
"video": item["snippet"]["title"],
})
i += 1
I used minhashing to map video titles to slot machines.
import pandas as pd
from datasketch import MinHash, MinHashLSH
def get_minhash(text, num_perm=128):
m = MinHash(num_perm=num_perm)
for word in set(text.lower().split()):
m.update(word.encode('utf8'))
return m
def find_best_match(coplay_raw, slot_db):
num_perm = 128
lsh = MinHashLSH(threshold=0.1, num_perm=num_perm)
title_minhashes = {}
# Build LSH index for slot_db titles
for idx, title in enumerate(slot_db["title"]):
mh = get_minhash(title, num_perm)
lsh.insert(idx, mh)
title_minhashes[idx] = mh
best_matches = []
scores = []
# Find best match for each video
for video in coplay_raw["video"]:
video_mh = get_minhash(video, num_perm)
candidates = lsh.query(video_mh)
best_score = 0
best_match = None
for idx in candidates:
score = video_mh.jaccard(title_minhashes[idx])
if score > best_score:
best_score = score
best_match = slot_db["title"].iloc[idx]
best_matches.append(best_match if best_match else "No Match")
scores.append(best_score)
coplay_raw["best_title_match"] = best_matches
coplay_raw["match_score"] = scores
return coplay_raw
updated_df = find_best_match(coplay_raw, slot_db)
display(updated_df)
This produced a table like:
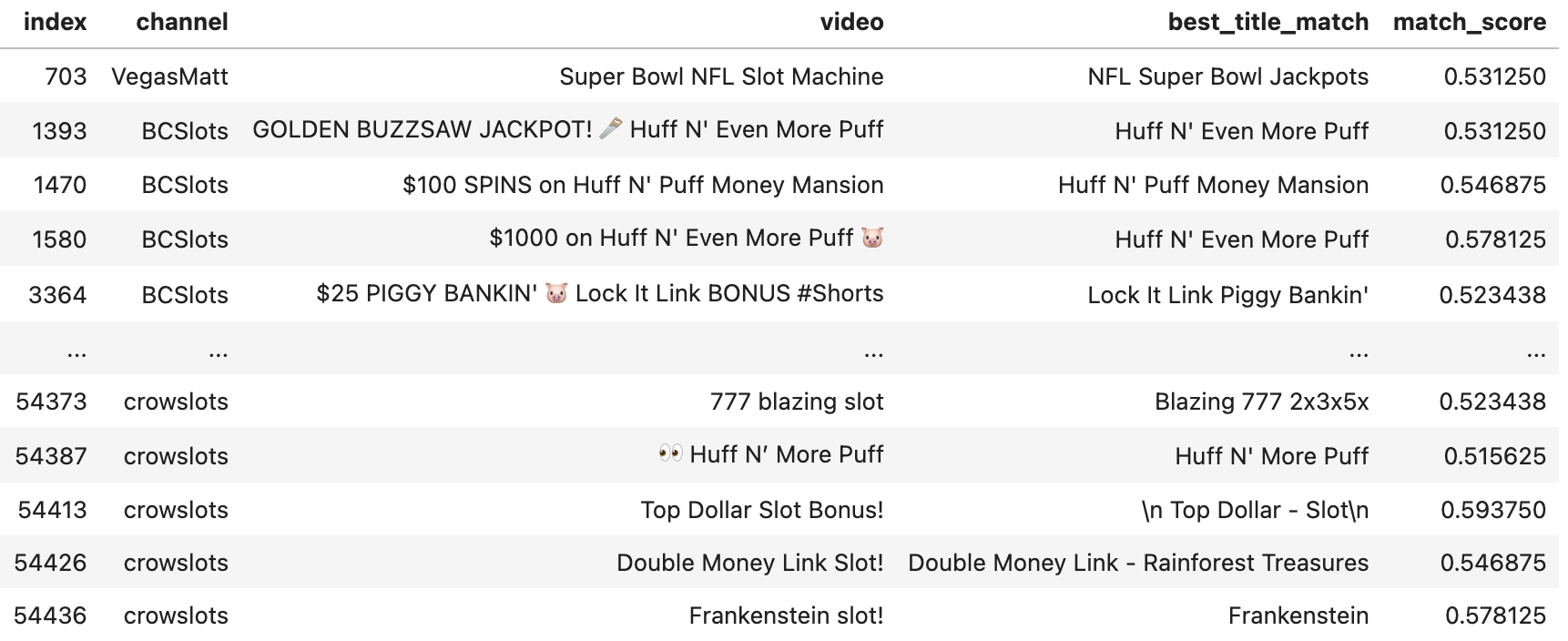
By spot checking I was able to map the minhashing score to probability that the mapped slot machine is correct:
def get_probability(score):
if score < 0.1:
return 0.0
elif score < 0.15:
return 0.1
elif score < 0.2:
return 0.15
elif score < 0.25:
return 0.2
elif score < 0.3:
return 0.35
elif score < 0.35:
return 0.5
elif score < 0.4:
return 0.7
elif score < 0.45:
return 0.8
elif score < 0.5:
return 0.9
elif score < 0.55:
return 0.95
else:
return 1.0
There are 54,787 plays from 50 different channels, with probability of a correct match averaging 17%.
I used coplays to build embeddings using a Word2Vec-style embedding algorithm. Then I clustered with DBSCAN.
import pickle
from gensim.models import Word2Vec
import numpy as np
from sklearn.cluster import DBSCAN
with open("sentences.pkl", "rb") as f:
sentences = pickle.load(f)
model = Word2Vec(sentences=[x.split() for x in sentences], vector_size=100, window=1000, min_count=15, workers=4)
words = list(model.wv.index_to_key)
word_vectors = np.array([model.wv[word] for word in words])
# Cluster the word vectors using DBSCAN
dbscan = DBSCAN(eps=1.5, min_samples=2)
labels = dbscan.fit_predict(word_vectors)
# Organize words by cluster
clusters = {}
for word, label in zip(words, labels):
if label not in clusters:
clusters[label] = []
clusters[label].append(word)
# Print the clusters
for label, cluster_words in clusters.items():
if label == -1:
print(f"Noise:")
else:
print(f"Cluster {label}:")
for word in cluster_words:
print(f" {word}")
The Word2Vec "sentences" each represent a channel. The "words" are slot machines. In order to get multiple sentences per channel, I sample the set of slot machines I include in each sentence. The order is always the order that they played the slot machines. Because the probability that I have a correct mapping is less than 100%, I sampled each machine proportionally to the probability that it was a correct mapping.
sentences = []
for _ in range(10): # Loop 10 times
for channel, group in updated_df.groupby('channel'):
words = [
title.strip().replace(" ", "-")
for title, score in zip(group['best_title_match'], group['match_score'])
if np.random.rand() < get_probability(score) * 0.5
]
sentence = " ".join(words)
sentences.append(sentence)
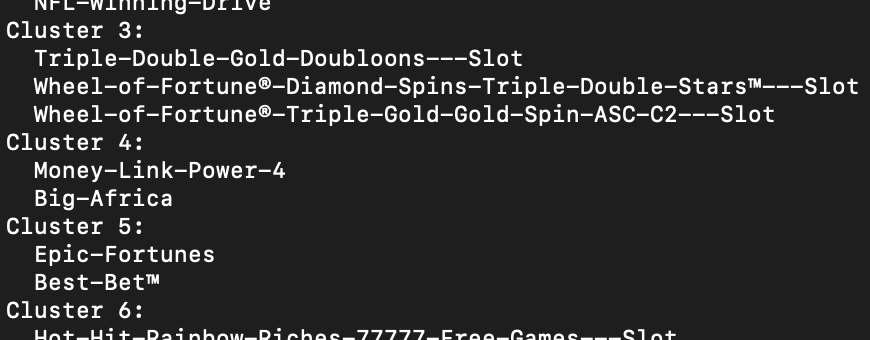
This produced seemingly meaningful clusters, but not obviously useful on their own:
Here are a couple of insights we could infer from the set of data we pulled.
Most popular slot machines:
Huff N More Puff and Journey to Planet Moolah are the two slot machines that are most likely to be played by the same channel.